컴퓨터 사이언스/신경망 기초
파이썬을 이용한 뉴럴 네트워크 실전 - 손실함수
KanzesT
2022. 1. 6. 18:37
● 기계학습중 딥러닝 방법은 데이터 주도 학습이다.
기존의 방법론에서는 사람이 특정 패턴과 알고리즘을 찾아내는, 사람의 개입이 필수적인 방법이였다. 하지만 기계학습에서는 사람의 개입이 최소화 되어있으며, 수집한 데이터로 부터 그 패턴을 찾으려는 시도를 하게 된다. 이를 종단간 기계학습 (end-to-end machine learning) 이라한다. 처음부터 끝까지 (데이터 입력부터 목표결과 출력까지) 사람의 개입 없이 얻어진다는 뜻을 담고 있다.
● 데이터는 훈련데이터(training data) 그리고 실험데이터(test data)로 나뉜다.
훈련데이터와 실험데이터를 나눠야 하는 이유는 바로 어느 데이터는 해석할 수 있는 범용능력을 실험데이터로 평가하여야 하기 때문이다.
훈련데이터는 최적의 매개변수를 찾기 위해 사용되며, 실험데이터로 앞서 훈련한 모델의 성능을 평가한다.
만일 실험데이터가 따로 존재하지 않는다면 실험데이터 외의 임의의 데이터를 인지할 수 있는 능력인 범용성을 평가할 수 없다.
한개의 데이터셋에만 지나치게 최적화되며, 다른 임의의 샘플의 인식률이 극히 떨어지는 일을 오버피팅 (overfitting) 이라고 한다.
▶손실함수
가장 많이 쓰이는 손실함수는 평균 제곱 오차(mean squared error) 이다.
이는 앞선 포스팅에 설명되어 있다.
https://blog.naver.com/kanzest/221528705323


그 이외의 다른 손실 함수로서 교차 엔트로피 오차 (cross entropy error, CEE) 또한 자주 사용된다.
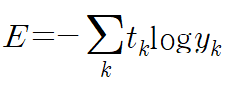
t_k = k번째 인덱스의 실제 값
y_k = k번째 인덱스의 출력 값
이를 파이썬으로 코딩한 예제이다.
------------------------------------------------------------------------------------------
import numpy as np
def cross_entropy_error(y,t): % 함수 정의
delta = 1e-10 % log(y)가 -inf이 되는 것을 방지
return -np.sum(t*np.log(y+delta))
t = [0,0,1,0,0,0,0,0,0,0]
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
print(cross_entropy_error(np.array(y), np.array(t)))
y = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
print(cross_entropy_error(np.array(y), np.array(t)))
------------------------------------------------------------------------------------------